
Tutoriel : Créez des images avec EasyDiffusion, un stable-diffusion en local
Des images en local, à volonté, avec un contrôle complet, ça change de Midjourney !
Midjourney, Dall-E... les modèles d'IA dite "générative" appliquée à la création d'image font régulièrement parler d'elles. Mais en pratique, elles sont souvent soit payantes, soit très limitées dans ce que l'on peut faire avec. Généralement exécutées dans le cloud, vous êtes tributaire de la bonne volonté, et des pratiques économiques, de l'hébergeur du service. Et puis, quelle confidentialité quand les images sont littéralement générées par la machine de quelqu'un d'autre ? Aucune, sans doute.
Mais si je vous disais qu'il existe une IA que vous pouvez exécuter en local, sans avoir besoin d'une station de travail ultra-puissante, avec toutes les garanties qui vont avec ? Gratuité, illimité, confidentialité, liberté, et personnalisation infinie, avec des dizaines et des dizaines de modèles téléchargeables gratuitement pour les mettre au boulot ? Cette IA, c'est stable-diffusion. Vous en avez peut-être déjà entendu parler, mais faire fonctionner stable-diffusion n'est, en soi, pas une mince affaire.
Heureusement, de gentils passionnés vous ont mâché le travail avec une distribution toute faite. Installée et lancée en quelques clics, elle vous permet de vous lancer en quelques minutes. Cette distribution, c'est EasyDiffusion. Voyons ensemble ce qu'elle est, ce qu'elle propose, comment elle marche et comment en tirer le meilleur profit avec ce petit tutoriel...
Installer, lancer, patienter...
La première chose à savoir avant de vous lancer, c'est que pour utiliser EasyDiffusion, il va quand-même falloir être un peu patient, et lui faire un peu de place, à tous points de vue. Il va être gourmand en espace disque, en RAM, et en mémoire vidéo.
D'abord, avez-vous une carte graphique nvidia ? Si ce n'est pas le cas, honnêtement, il vaut mieux vous arrêter là. Les cartes AMD et Intel ne sont pas prises en charge par Easy Diffusion. Et la génération au CPU, bien que possible, est abominablement lente. Vous allez vous arracher les cheveux et il existe des outils plus adaptés.
Pour ceux qui ont bien une carte graphique nvidia (geforce ou quadro), vous pouvez continuer la lecture.
Bien qu'il soit en théorie possible de le faire tourner sur un PC doté de 8Go de RAM et de 2Go de VRAM, en pratique, pour être réellement à l'aise il faut compter plutôt 16-32Go de RAM et un GPU avec 8Go de VRAM pour faire tourner les modèles de base. Et même plutôt le double pour être à l'aise sur les tous derniers modèles. Il faudra aussi préparer de l'espace sur le disque dur.
Vous trouverez en bas de cette page le lien vers l'installateur. Celui-ci pèse à lui seul pas moins de 1,8 Go, mais ce n'est que la première étape. Car il va ensuite décompresser de nombreux fichiers et en télécharger d'autres. Attendez-vous à patienter quelques minutes même avec un PC rapide et un SSD.
Une fois l'installation terminée, c'est déjà 10,8 Go occupés. C'est bon, c'est fait ?
Alors rendez-vous dans le répertoire d'installation et cliquez sur "Start Stable Diffusion UI.cmd". Après quelques secondes à quelques minutes d'attente, le temps qu'il s'initialise pour la première fois, un nouvel onglet s'ouvre dans votre navigateur. C'est depuis cette interface que tout se joue.

Bien qu'il y ait de nombreux paramètres, vous pouvez immédiatement tester le bon fonctionnement d'EasyDiffusion en générant vos premières images. Saisissez votre prompt (de préférence en anglais, le français peut fonctionner mais est nettement moins bien compris), par exemple, "The quick brown fox jumps over the lazy dog". Vous verrez alors une barre de progression et au bout de quelques secondes à quelques minutes, de premières images apparaître.
À ce stade, le résultat devrait être assez vilain, mais pas de panique, c'est plutôt normal, nous verrons après comment améliorer (nettement) le résultat. Pour l'instant, on veut juste vérifier que ça marche.
Ça marche pas !
Si ce n'est pas le cas, vérifiez le message d'erreur. Les deux plus classiques sont le manque de mémoire vive, et le manque de mémoire.
Si vous manquez de RAM centrale, vous devriez voir une erreur de ce type :
Error: Could not load the stable-diffusion model! Reason: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 58982400 bytes.
Reason: Your computer is running out of system RAM!Si c'est la VRAM, côté GPU, qui vient à manquer, l'erreur devrait ressembler à :
RuntimeError: CUDA out of memory. Tried to allocate 30.00 MiB (GPU 0; 6.00 GiB total capacity; 5.16 GiB already allocated; 0 bytes free; 5.30 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Dans le premier cas, il faudra libérer de la RAM sur votre PC en fermant des logiciels, et au besoin, ajouter de la mémoire virtuelle (swap) dans Windows. N'oubliez pas que stable-diffusion est un modèle assez gourmand. Si vous n'avez vraiment pas assez de RAM sur votre machine, vous ne pourrez peut-être pas le faire tourner.
Dans le second, vous devrez peut-être fermer certains logiciels consommateurs de VRAM (par exemple Photoshop, ou si vous lisez des vidéos en même temps). Mais il y a aussi un petit réglage possible. Rendez-vous dans les paramètres via l'onglet en haut de la page :
Dans la liste des paramètres qui s'affiche alors, cherchez GPU Memory Usage : par défaut, le réglage est à "Balanced", mais vous pouvez essayer de le réduire à "Low". La qualité du résultat ne changera pas et la VRAM consommée sera considérablement réduite. En revanche, la génération sera plus lente. Cela permettra d'utiliser stable-diffusion avec une Geforce GTX 960, voire avec une 780, à condition de ne pas utiliser des modèles trop gourmands.
Si pour une raison ou pour une autre vous ne pouvez vraiment pas utiliser votre GPU, vous avez juste en-dessous l'option "Use CPU (not GPU)" mais comptez, dans ce cas, sur une vitesse de génération en gros divisée par 100. Oui... vous allez LITTÉRALEMENT y passer la nuit, pour générer quelques essais.
Ça marche, mais c'est moche !
Pas de panique, c'est normal. Commençons par passer en revue les principales options pour voir comment elles influencent le résultat.
Enter prompt : saisissez, en anglais de préférence, ce que vous voulez générer. Soyez précis, n'hésitez pas à ajouter des détails sur le style, la qualité, etc. à l'aide de mots-clés. Plutôt que "A dog in the park", précisez par exemple "Beautiful photo of a dog frolicking in the park. Photoshoot, exterior, high quality, masterpiece, natural light."
+ image modifiers : les image-modifiers sont des pré-réglages qui viennent s'ajouter à votre prompt. L'interface laisse croire à quelque chose de particulier, mais ce n'est pas le cas. Choisir l'image modifier "lithography" ou écrire vous même "lithography" à la fin de votre prompt revient strictement au même et génèrera exactement la même image. Le seul intérêt de cette fonctionnalité est de vous offrir une petite interface qui vous présente des idées de mots-clés à ajouter, avec un petit aperçu de l'effet visé.
+ Embedding : bien que les embeddings ne soient pas des modèles, nous reparleront de ces derniers dans la section consacrée aux modèles, vu leur influence sur ces derniers.
Negative prompt : ici, saisissez au contraire tout ce que vous ne voulez pas. C'est le moment de prendre tous les défauts que vous avez constaté dans vos premières générations et de les ajouter ici. Par exemple : "bad anatomy, extra limb, missing limb, extra fingers, missing fingers, bad quality, low quality, artifacts, watermark, blurry, oversaturated, poor quality"
Initial image (img2img) : cela permet ou bien de donner une image qui va servir de guide à stable-diffusion, ou bien de faire de l'inpainting. L'inpainting, ça consiste à lui donner une image, à déterminer une zone à "redessiner", à lui dire quoi redessiner et à le laisser tenter de combler la zone déterminée, en s'aidant de tout ce qu'il y a autour. Les résultats peuvent être plus ou moins convaincants, mais cela permet parfois de prendre une image générée dont vous êtes satisfait sauf UN détail qui vous embête, et de faire regénérer juste cette partie là.
Puis, dans les "Image Settings" :
Seed : laissez généralement à "Random". Chaque "seed" donnera des résultats aléatoires. La seule raison de garder une même seed est de régénérer la même image avec des réglages légèrement différents.
Number of images : combien d'images générer (et combien en même temps).
Model : On y reviendra dans la section appropriée.
Clip Skip : En gros, cela rend la compréhension de votre prompt moins précise. Cela peut paraître contre-intuitif, mais cela peut, dans certains cas et pour certains modèles, amener à de meilleurs résultats. De manière générale cependant, si vous n'avez pas de raison particulière de l'utiliser, il vaut mieux le désactiver.
ControlNet : il s'agit ici de donner au modèle une image qui va servir de guide, un peu à la manière de l'image2image, mais plus spécifiquement ici, il s'agit d'aider le modèle à comprendre la forme de ce que vous voulez dessiner. Par exemple, dessiner un croquis avec des personnages dans une position précis, et le modèle dessinera vos personnages dans cette position. Cela ne fonctionne que si l'image est suffisamment "claire". Par exemple si le sujet principal se détache nettement du fond, cela facilitera le travail du modèle.
Custom VAE : les VAE sont des modèles entraînés à améliorer certains aspects spécifiques des images générées. Par défaut, le modèle vae-ft-mse-840000-ema-pruned est inclus, il permet d'améliorer la génération des visages (en particulier les yeux) humains. Vous devrez peut-être le désactiver dans certains cas particuliers (par exemple si vous cherchez volontairement à créer un personnage monstrueux à trois yeux).
Sampler : les différents samplers vont interpréter légèrement différent vos prompts et entraîner une génération différente même avec une même seed, un même prompt et un même modèle. Différents modèles auront différents avantages et inconvénients. Par exemple, certains sont plus aléatoires que d'autres. Certains sont plus rapides que d'autres. Certains sont plus à l'aise avec un nombre réduit de Steps (voir ci-dessous) alors que d'autres pas du tout...
Par exemple, les sampler "Ancestral" sont dits non-convergents car ils ont une plus grande part d'aléatoire à chaque étape. On peut dire en gros qu'à chaque step, l'image générée via un sampler ancestral se "transforme", alors qu'à chaque step avec un modèle non-ancestral, l'image générée "s'affine". Exemple :

En haut, un sampler Ancestral, en bas, un sampler proche, mais non-ancestral à différentes étapes. Observez comme le chien a une forme plus ou moins définitive avec le sampler du bas, tandis que la forme de sa tête et de ses oreilles ne cesse de changer avec celui du haut.
C'est donc un premier choix à faire. Pour le reste, il faudra sans doute expérimenter un peu. Prenez un prompt dont vous êtes satisfait, choisissez une seed fixe (désactivez "Random") et testez différents samplers pour voir les différences. Mon expérience et mon avis personnel est que les meilleurs résultats sont obtenus avec les samplers DPM2 et DPM++ 2m (Karras). Les autres m'ont paru nettement moins convaincants et beaucoup plus sensibles au nombre de steps. Certains sont en revanche très rapides, ce qui peut permet d'expérimenter rapidement différents prompts, puis de switcher sur un sampler plus lent mais plus propre lorsque vous avez trouvé un prompt qui vous convient.
Image Size : c'est tout simple, la taille et le format de l'image, rien de compliqué n'est-ce pas ? Sauf que les modèles sont étonnamment sensibles à ce paramètre. La plupart des modèles sont incapables de générer une image correcte si sa taille est trop petite, d'autres sont gênés par une image trop grande, certains sont plus à l'aise avec les images carrées, d'autres avec le format portrait, d'autres encore avec le format paysage... Choisir le bon format est donc tout un art. En règle générale, il vaut mieux générer une image pas trop grande et l'upscaler ensuite. Sans descendre en dessous de 512x512. Il est, du reste, préférable de rester sur des multiples de 256 (512, 768, 1024... évitez 256 qui est insuffisant pour la plupart des modèles).
Inference Steps : les fameuses steps dont on parle depuis tout à l'heure sont là. C'est le nombre de passes que vont faire le modèle et le sampler pour passer d'une image constituée de bruit aléatoire à une image définie. En général, plus vous définissez d'étapes d'inférence, moins l'image aura de défauts majeurs. Cependant, selon les prompts, les samplers et le hasard, il peut arriver qu'un nombre trop élevé d'étapes ruine l'image au lieu de l'améliorer.
Les meilleurs modèles commencent à donner une image exploitable à partir d'une quinzaine d'étapes, une image propre et détaillée autour des 25, et parfois il sera nécessaire de monter la valeur à 50 ou plus pour gommer certaines erreurs de génération. Je pense que la valeur par défaut de 25 est une bonne base de travail, mais là encore n'hésitez pas à faire des expériences de votre côté.
Guidance Scale : ce paramètre définit à quel point l'image essayera de coller au plus près de votre prompt. Plus la valeur est élevée, plus le modèle essaye de respecter à la lettre vos instructions, tandis qu'une valeur plus basse le rendra plus créatif. Mais attention : même si vous savez exactement ce que vous voulez, il n'est pas nécessairement futé de se dire "je vais juste fixer la valeur au maximum". En effet, plus le modèle essaye de respecter votre prompt, plus le risque de se planter complètement et de créer une abomination qui file des frissons rien qu'à la regarder est élevée, s'il se trouve que le modèle ne parvient pas à vous comprendre, ou à générer quelque chose de conforme.
Il est donc préférable de partir d'une valeur pas trop élevée, et de monter progressivement si vous trouvez que le modèle prend trop de libertés avec vos instructions.
LoRA : nous y reviendront dans la section réservée aux modèles.
Seamless Tiling : utile principalement lorsque vous générez des textures (à moindre mesure des paysages), le seamless tiling permet de créer des images qui peuvent être placées côte à côte, "en mosaïque", sans que la frontière entre les images ne soit apparente. Ce paramètre peut néanmoins réduire la qualité de la génération, il est donc préférable de ne l'activer qu'en cas de nécessité pour un besoin précis. À noter que le seamless tiling produit ses meilleurs résultats sur les images de format 512 x 512 pixels.
Output format : jpeg, png ou webp, au choix. Je recommande personnellement png, même si c'est un format volumineux pour les photos, pour son caractère lossless. Si vous n'avez pas une place infinie cependant, un jpeg ou un webp pas trop compressé fera l'affaire.
Enable VAE Tiling : si vous générez de grosses images, activez cette fonctionnalité pour réduire un peu l'empreinte mémoire de la génération.
Show live preview : mieux vaut décocher cet aperçu instantané, assez désagréable à regarde, consommateur de VRAM et qui ralentit la génération.
Fix incorrect faces and eyes : Un autre paramètre permettant d'ajouter un modèle dont le rôle est d'améliorer, spécifiquement, les yeux et les visages. Contrairement au VAE, ici on ne parle que de modèles ayant cette tâche. Alors que dans le cas du VAE, si le modèle fournit par défaut a cette fonctionnalité, rien ne vous interdit d'importer d'autres modèles ayant d'autres tâches. Là encore, pensez à désactiver cette fonctionnalité si vous souhaitez volontairement générer des visages "amochés" ou non-humains. Du reste, même sur un visage humain normal, cette fonctionnalité n'est pas toujours pertinente, elle a notamment tendance à lisser et à faire perdre de la texture. Un prêté pour un rendu, donc.
Scale up by : permet d'activer l'upscaling par défaut. Je ne conseille pas cette fonction, gourmande et lente. Upscaler toutes les images, alors que vous allez générer énormément de déchets, ne fera que vous ralentir. Mieux vaut réserver l'upscaling aux images qui vous plaisent particulièrement et que vous comptez exporter, puisqu'EasyDiffusion permet de le faire au stade ultérieur, après la génération, sur une image en particulier (voir plus bas).
Show only the corrected/upscaled image : permet de n'afficher que les images après application des deux paramètres ci-dessus. Bien sûr, pas d'effet si les deux paramètres sont désactivés.
Bon, et cette histoire de modèles, alors ?
Les modèles, on y arrive ! C'est assez important, puisque c'est eux qui vont interpréter votre prompt et générer une image. Easy Diffusion en supporte de deux types : les modèles complets ("Model") et les LoRA, qui sont des genres de modèles "partiels" qui viennent en complément d'un modèle principal, sans le remplacer. Il existe également des embeddings, qui ne sont pas à proprement parler des modèles mais participent néanmoins à enrichir les précédents. Il existe, enfin, un dernier type de modèle (les hypernetworks) qui ne semble plus pris en charge par les dernières versions d'Easy Diffusion. La raison est probablement que les hypernetworks ont la même utilité que les LoRA, tout en produisant généralement de moins bons résultats.
EasyDiffusion est fourni avec un seul modèle principal (stable-diffusion 1.5), aucun LoRA, et aucun embedding. Il faudra donc les télécharger et les placer dans le répertoire approprié. Vous trouverez en bas de page un lien vers le principal site de téléchargement de modèles, nommé CivitAI.
À ce sujet, un petit avertissement : il semble que stable-diffusion soit massivement utilisé par des gens qui cherchent à générer des images capables de répondre à leurs fantasmes. Si CivitAI ne vous montrera aucun modèle ouvertement pornographique sans que vous l'ayez explicitement demandé (le filtre nsfw étant activé par défaut), vous verrez nombre de modèles consacrés à la génération de deepfakes de telle ou telle célébrité, ou à la génération d'images de type fan-service japanime/manga (comprendre : pour faire des waifu en petite tenue ou sans tenue du tout). Ne soyez pas surpris.
À présent, revenons-en aux modèles :
Les modèles complets/principaux :
Il s'agit là de remplacer le modèle généraliste et fourni par défaut de stable-diffusion 1.5. Vous pouvez ainsi choisir parmi d'autres modèles généralistes ayant leurs propres qualités et leurs propres défauts, et nombre de modèles plus ou moins spécialisés. Rarement repris de zéro, il s'agit généralement de modèles basés sur l'un des principaux modèles préexistants, mais avec un entraînement supplémentaire pour y apporter des nouveautés. Il faudra donc les télécharger, et les importer.
Voici quelques exemples :
SDXL :
Le plus important à connaître est probablement le modèle "SDXL". C'est-à-dire Stable Diffusion XL. Évolution majeure du modèle de stable-diffusion, vous pouvez le considérer comme un modèle "Stable-Diffusion 3.0" (oui, car il y a eu un 2.0, mais il est généralement ignoré pour n'avoir rien apporté d'utile). Considéré comme un progrès majeur à tous points de vue (capacité à comprendre à prompt, qualité des images générées), il a néanmoins un énorme défaut : il demande une machine dernier cri pour fonctionner correctement. 8Go de VRAM et 32Go de RAM principale suffisent à peine à lui permettre de démarrer, et sa vitesse de génération est très lente : comptez facilement 5 à 6x plus de temps pour générer une image avec SDXL qu'avec sd1.5.
Typiquement, SDXL se divise en deux modèles qu'il faut utiliser de manière consécutive. Le modèle de base s'occupe du gros œuvre et génère une première image approximative, que vous utilisez ensuite comme image de guidage pour le modèle dit "refiner", qui s'occupera de fignoler les détails. Sur une RTX 2070, comptez 1min30 environ pour générer une seule image à 15 étapes d'inférence avec SDXL base, puis 30 secondes supplémentaires pour affiner à 25 étapes d'inférence avec le Refiner, portant le total à 2 minutes par image.
DreamShaper 8 :
DreamShaper est une évolution de sd1.5 qui vise à se rapprocher des capacités de Midjourney. Si certains le voient volontiers comme un SDXL du pauvre, nous n'avons pas été plus emballés que ça par ce modèle, qui semble très mal supporter qu'on lui demande d'adhérer strictement au prompt, et peu à l'aise lorsqu'il s'agit de générer des images photoréalistes, préférant nettement le style "dessin numérique". Il peut néanmoins représenter une alternative intéressante, qui mérite d'être tentée, d'autant qu'il est relativement rapide et léger. En fait, il est préférable de prendre le titre "DreamShaper" à la lettre : il sera très bien pour mettre votre imagination en image, en lui laissant une certaine latitude pour créer un peu le rêve qu'il veut, et sans chercher quelque chose d'ultra-précis ou d'ultra-réaliste.
Anything V3/V5 :
Spécialisé dans les images de type anime/manga, il permet de générer personnages, animaux et décors avec un style "animation japonaise" vraiment convaincant. Bien entendu, pas question ici de lui demander quoi que ce soit de photoréaliste. En revanche, il est à l'aise sur un certain nombre de personnages de fiction dont sd1.5 semble n'avoir jamais entendu parler. Certaines images sont vraiment splendides, bien que sa compréhension des prompts soit imparfaite et qu'il ait tendance à faire de grosses approximations au niveau de l'anatomie (nombre de doigts, nombre de pattes des animaux...). Il faudra pas mal itérer pour obtenir des résultats vraiment convaincants mais il a quelque chose de charmant.
F222 :
Initialement conçu pour permettre de produire des nus convaincants, il semble en fait également tout à fait capable de faire de beaux portraits et de belles photos habillées. Attention quand-même, car un nu inopiné peut débarquer à tout moment. Bien entendu, sa spécialité à lui étant les photos de personnes, il n'est pas question de lui demander de faire un dessin crayonné de chiens dans un paysage de fantaisie. Ce n'est pas du tout sa spécialité, et il vous le fera clairement sentir si vous essayez quand même.
EpiCPhotoGASM :
Sous ce nom un peu barbare se cache un modèle spécialisé dans la photo réaliste de toutes sortes : portraits, photos de portraits plein-pied, objets, animaux, paysages... il donne des résultats très intéressants et sa compréhension des prompts est excellente (peut-être l'une des meilleures), tant que vous restez dans le domaine du photoréalisme. Fait amusant, photoréalisme ne veut pas dire exempt de fiction. Nous lui avons par exemple demandé de générer Sonic le hérisson en DJ sur une grosse console de mixage dans un club. À condition de lui donner suffisamment d'étapes d'inférence (une soixantaine quand-même), il s'est exécuté sans trop faire d'histoires :

Bon, oui, d'accord, à y regarder de près le résultat n'est pas parfait : Sonic a trois yeux et trois doigts à chaque main, mais rien qu'un peu d'inpainting ou de controlnet ne puisse corriger, et le contrat du photoréalisme est globalement respecté. Il est à noter qu'une grosse console de mixage est un travail particulièrement exigeant pour les générateurs d'image, au vu du nombre de petits détails (nombreux potentiomètres, curseurs, boutons et LED) qui peuvent donner lieu à de nombreuses incongruités. De ce point de vue, le modèle s'en sort extrêmement bien. La cohérence spatiale est typiquement le genre de choses sur lesquelles sd1.5 est parfaitement largué.
Et tant d'autres...
Il existe littéralement des centaines de modèles à télécharger et à essayer. Certains sont basés sur sd1.5, d'autres sur SDXL (ceux-là seront donc plus gros et plus gourmands, mais sans doute plus précis). Mais attention... un modèle de ce type prends en règle générale entre 2 et 8 Go. Si vous vous mettez à ajouter quelques dizaines de modèles, votre répertoire EasyDiffusion risque vite de grossir de manière incontrôlée.
Et c'est notamment pour ça que l'on a inventé...
Les LoRA :
Les LoRA sont des sortes de modèles partiels, entraînés à une tâche particulière, qui vont transformer l'image, modifier la compréhension du prompt, apporter au modèle des connaissances qu'il n'a pas pour l'aider à générer des images spécialisées, etc. Nettement plus petits que les modèles complets (quelques dizaines à quelques centaines de méga-octets) Ils sont souvent "déclenchés" à l'aide de mots-clés, ou lorsque le prompt se rapporte à leur domaine de spécialité. En revanche, activer un LoRA avec un prompt grossièrement incompatible (par exemple un LoRA spécialisé dans le style manga, alors que vous avez indiqué dans votre prompt vouloir une image photoréaliste) peut donner des résultats inattendus et généralement très vilains.
Pour mieux comprendre l'intérêt des LoRA, prenons le prompt suivant, inspiré de celui utilisé plus haut dans l'article :
"Beautiful image of a dog frolicking in the park. Exterior, high quality, masterpiece, natural light. Ghibli-style."Voici l'image obtenue sans LoRA :

Pas vilain (si on n'y regarde pas de trop près), mais pas ce que j'ai demandé. Moi, je voulais une image dans le style Ghibli.
Maintenant, même prompt, même seed, même nombre d'étape d'inférence, même format, même tout, à un détail près : nous avons rajouté un LoRA spécialisé dans le "style Ghibli", justement. Et voilà le résultat obtenu :

Pour un coût de seulement 144Mo, nous avons radicalement transformé notre modèle de base afin d'obtenir quelque chose qui nous convient. Mais cela va plus loin, car l'intérêt des LoRA est aussi de pouvoir leur attribuer un poids. Plus ce poids est élevé, plus l'image est transformée. Il est ainsi possible de créer des "hybrides", sans avoir à réentraîner un modèle neuf à chaque fois.
Reprenons notre prompt, avec différents niveaux de poids de notre LoRA Ghibli :

Même modèle, même LoRA, même tout, mais le poids du LoRA est fixé à 0.5 : on note un début de transformation, le sol fait un peu plus dessin animé, le chien est moins réaliste, mais on n'est pas encore vraiment dans un style dessin d'animation japonaise.
Poussons donc un peu plus loin :

Le LoRA est ici fixé à 0,8, la transformation continue doucement, le chien continue à se cartooniser, l'herbe et le sol aussi, notamment au niveau de la lumière. Poussons à 1 :

On retrouve notre image de tout à l'heure. Mais imaginons que ça ne nous suffise pas... on peut en fait pousser le LoRA au-delà de 1, avec des résultats plus ou moins heureux. Ci-dessous, le LoRA poussé à 1,5 :

Le chien s'en trouve changé de race ! L'ombre n'est plus du tout photoréaliste, la lumière est beaucoup plus plate (on a perdu tout effet de lumière au sol)... De là à dire que c'est plus Ghibli ou moins Ghibli, ça se discute... Mais en tout cas, le résultat final est modifié.
Voilà à quoi servent les LoRA et comment les utiliser. Et ce qui est amusant, c'est que rien ne vous interdit d'en cumuler plusieurs, tant qu'il n'y a pas d'incompatibilité grossière (vous ne pouvez pas à la fois utiliser un LoRA qui donne un style "photo" et un qui donne un style "dessin au crayon", ça ne donnera rien de valable, mais vous pouvez cumuler un LoRA "style ghibli" et un LoRA "style pixel art", et vous obtiendrez un chien kawai en pixel art).
Les embeddings :
Vous avez peut-être repéré le petit bouton "+ Embedding" au-dessus du prompt, mais aucun n'est fourni avec EasyDiffusion. Ces petits fichiers ne sont pourtant pas dénués d'intérêt. occupant à peine quelques dizaines de kilo-octets, ils vont apporter à votre modèle un gain de vocabulaire, voire changer leur compréhension du vocabulaire préexistant, le tout sans modifier le modèle de base. Très petit car entraînés sur un très faible nombre d'images, ils sont en général hyper-spécialisés et utilisés pour une tâche bien précise. Ces embeddings sont par exemple souvent utilisés pour apprendre à un modèle à générer un visage ressemblant à une célébrité en particulier, pour redéfinir un mot afin de varier sa génération, ou encore pour définir au modèle ce qu'est une image "moche" qu'il ne doit surtout pas générer (un embedding négatif constitué à partir de quelques mains à 12 doigts devrait ainsi aider le modèle à éviter de produire ce genre d'erreurs).
Voilà en gros pour les modèles, vous avez maintenant de quoi générer tout ce qui vous passe par la tête, comme ça vous passe par la tête.
Télécharger et importer des modèles
Sur le site de CivitAI (lien ci-dessous), vous pourrez chercher des modèles, des LoRA, des embeddings etc. Il faudra généralement créer un compte pour les télécharger, gratuitement. Vous devrez les placer dans des répertoires bien précis.
Mettons que vous avez installé Easy Diffusion dans le répertoire C:\EasyDiffusion : vous devrez alors placer les modèles dans les répertoires suivants :
Modèles complets : C:\EasyDiffusion\models\stable-diffusion
LoRA : C:\EasyDiffusion\models\lora
Embeddings : C:\EasyDiffusion\models\embeddings
Une fois les modèles placés dans leur répertoire, vous devrez peut-être redémarrer Easy Diffusion pour qu'ils soient détectés. Vous pourrez ensuite les sélectionner et générer vos images à l'aide de ces nouveaux modèles.
Après la génération
Vous avez généré vos images, mais vous pouvez encore jouer avec pour affiner le résultat. Passez votre curseur sur l'image de votre choix, et des options apparaissent en superposition :
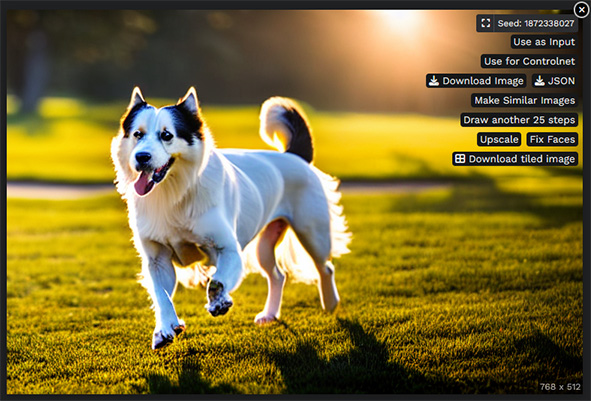
Certaines de ces options se comprennent très bien d'elles-mêmes (Download image par exemple). D'autres méritent sans doute qu'on s'y attarde :
Use as Input : permet d'utiliser l'image en Initial image (img2img), par exemple pour l'arranger avec de l'inpaiting.
Use for ControlNet : là encore, on réutilise l'image en entrée pour en produire une autre, mais ici sous forme de ControlNet (voir ci-dessus), c'est à dire essentiellement pour guider la composition.
JSON : Permet de télécharger un fichier .json (fichier texte) qui contient votre prompt, tous vos réglages et la seed utilisée. Sous réserve que la personne possède les mêmes modèles que vous, vous pourrez envoyer ce fichier à quelqu'un et il pourra générer de son côté exactement la même image.
Make similar images : permet de générer 5 images similaires à celle choisie : l'image choisie est utilisée en entrée, le prompt de l'image est réutilisé, la plupart des réglages sont conservés mais la seed change et certains réglages (Guidance scale et Prompt Strength notamment) sont pré-réglés à des valeurs par défaut. Très utile quand vous aimez bien la composition et l'idée générale d'une image, mais que vous souhaitez tester d'autres détails. Par exemple, sur l'image ci-dessus, vous aurez un chien en position à près identique sur un décor à peu près identique, mais la race du chien pourra varier, l'herbe être légèrement différente, et selon la précision du prompt, le style graphique pourra également varier. Ici il ne variera pas car nous avons été très spécifique sur le fait que nous voulions une photo réaliste avec un type de lumière précis, mais si nous ne l'avions pas fait, le style pourrait changer.
Draw another 25 steps : vous avez généré une image avec peu d'étapes d'inférence, le résultat va dans le bon sens, mais il y a encore des "bugs" graphiques importants ? Générez la même image avec 25 étapes d'inférence de plus et avec un peu de chance, cela devrait gommer ces défauts sans changer radicalement l'image (surtout si vous n'avez pas utilisé un sampler ancestral).
Upscale : agrandit l'image à l'aide d'un modèle d'upscaling basé sur l'IA. En pratique, l'upscaling se fait en x4 avec le modèle Real-ESRGAN (équivalent à cocher l'option "Scale by up to" dans les options avant la génération). Ainsi, une image en 512x512 passera en 2048*2048 : en réalité c'est donc une image avec 16x plus de pixels (x4 en longueur + x4 en hauteur). Pratique pour un upscaling rapide, mais pour plus de contrôle sur votre upscaling, il peut être avantageux d'enregistrer l'image et de l'importer dans un outil d'upscaling plus complet comme Upscayl.
Fix faces : Tente de corriger les visages à l'aide du modèle GFPGan (équivalent à cocher l'option "Fix incorrect faces and eyes" dans les options avant la génération).
Download tiled image : essentiellement utile si vous avez généré une texture et que vous avez activé "Seamless tiling", permet de télécharger en une seule fois l'image recopiée et alignée en mode "mosaïque".
Dernière option utile : si vous êtes globalement content de votre prompt et de vos réglages mais que vous souhaitez changer un petit point, vous pouvez cliquer sur le bouton "Use these settings" en haut du cadre contenant vos images. Vous récupèrerez le prompt et les réglages correspondants dans le cadre de gauche, que vous pourrez réutiliser et modifier à loisir.
Conclusion
Voilà, vous avez tous les éléments pour générer des images, tester et itérer. N'hésitez pas à faire vos propres expériences, à tester des prompts variés, positifs comme négatifs, à tenter de donner plus ou moins de détails, plus ou moins de mots-clés. À tester un même prompt avec différents modèles... il faudra souvent avancer par essai-erreur, générer parfois de nombreuses images avec un même prompt et les mêmes réglages pour que subitement, une image générée sorte du lot, et même là, il ne faudra pas hésiter à jouer avec les options tels que "Generate similar images" et avec l'inpaintig pour obtenir un résultat vraiment nickel.
Ce n'est pas grave, prenez votre temps... l'avantage, c'est que ça tourne chez vous, vous ne payez pas à l'image générée, vous êtes libre de faire autant d'essais que vous le voulez, alors profitez-en et amusez-vous !
| Ressources : |
|---|
