

Faites tourner votre propre ChatGPT avec LLaMa et Chatbox
Bon OK, pas vraiment ChatGPT, mais ça s'en rapproche pas mal
ChatGPT fut à ce point révolutionnaire qu'il a, à lui seul, provoqué le Printemps de l'IA. Il est si connu du grand public qu'on a fait le choix, sur EverydAI, de n'en parler que très rarement. Car il n'y a pas grand chose que l'on puisse en dire qui n'ait déjà été dit des centaines de fois dans toutes les langues et sur tous les tons, contrairement à LLaMa, le sujet de cet article. ChatGPT, c'est la face visible de l'iceberg de l'IA moderne, et c'est accessoirement un agent conversationnel pratique, amusant, divertissant, utile... beaucoup d'entre nous l'avons intégré à notre quotidien, avec plus ou moins de succès certes, mais quand même. Seulement, deux grandes préoccupations empêchent de s'en servir tout à fait sereinement.
La première, c'est celle de la confidentialité : fonctionnant uniquement dans le cloud, sur les serveurs d'OpenAI, tous vos échanges sont enregistrés, susceptibles d'être lus, utilisés pour entraîner le modèle et éventuellement, répétés par ce dernier. La confidentialité est à peu près inexistante, ce qui n'est pas sans poser son lot de questions de vie privée, notamment si vous discutez avec lui de sujets intimes.
La deuxième, c'est le coût : s'il existe une version gratuite, celle-ci est limitée et basée sur GPT-3.5, un modèle qui se fait aujourd'hui vieillissant et pas très pertinent. Sinon, il vous faut payer au moins 24$ TTC/mois (20$ HT), et plus si vous avez des besoins spécifiques pour accéder à GPT-4.
LLaMa 3 à la rescousse !
Mais aujourd'hui, une autre solution existe : Meta, la maison-mère de Facebook, a mis à disposition du public son propre modèle de langage, intitulé LLaMa. La dernière version, LLaMa 3, est open-source, gratuite, accessible au plus grand nombre, même pour un usage commercial, elle n'est pas tout à fait un logiciel libre mais presque. N'importe qui peut donc s'en servir, la télécharger et l'utiliser comme bon lui semble.
Et ça n'a pas traîné : en quelques jours, la communauté s'est emparé du modèle et conçu des solutions pour l'exécuter en local sur sa propre machine.
Pour bien comprendre de quoi il est question, une première précision, et on en profite pour faire un petit point vocabulaire : LLaMa 3 est disponible en deux versions principales :
- Une version à 70 Milliards de paramètres, plus précise, plus "intelligente" mais aussi plus volumineuse. On l'appelle généralement 70B, retenez ce nom.
- Et une version à 8 Milliards de paramètres, ou 8B, plus petite mais un peu moins futée, plus limitée.
Ensuite, chaque version dispose typiquement de plusieurs sous-versions. En particulier, un terme qui reviendra souvent est celui de la quantisation. En deux mots : le modèle de base utilise des modèles mathématiques avec une précision à 16 bits. Mais il est possible de réduire la précision à 8, 6, 5, 4 ou même seulement 2 bits. Le résultat, c'est là encore un modèle moins volumineux, mais potentiellement moins précis.
En pratique, on considère qu'entre 16 et 8 bits, il n'y a aucune différence perceptible. Que jusqu'à 6 bits, la différence est négligeable. Qu'à 5 bits, il y a une perte d'intelligence mais que cela reste satisfaisant. En dessous, la perte de qualité commence à devenir vraiment gênante.
Tous ces modèles sont désormais en ligne, téléchargeables, exploitables. Mais tous ne seront pas forcément adaptés à une utilisation en local sur un PC de particulier. Nous y reviendrons.
Ollama et Chatbox : les outils communautaires pour une utilisation facile de LLaMa 3
"LLaMa 3 est open-source, ok, c'est super. Mais moi, je suis pas développeur. Devant un code source, je suis comme une poule devant un couteau. Comment je fais pour utiliser LLaMa 3, concrètement ?"
On y vient, on y vient. Rassurez-vous, la communauté autour des LLM open-source est très active et a fait tout le nécessaire pour que vous puissiez facilement utiliser le modèle de langage de votre choix. Vous aurez besoin de deux outils, et encore, l'un des deux est techniquement facultatif.
Comme d'habitude, vous trouverez tous les liens vers les outils en bas de l'article.
Le premier, c'est Ollama. Disponible pour Windows, Linux et macOS, vous avez juste à le télécharger et à l'installer. Sous Windows, c'est un exécutable d'installation tout ce qu'il y a de plus classique.
Une fois installé, il se trouve dans votre menu Démarrer, vous pouvez donc le lancer en un clic, très simplement. Il fonctionne alors en tâche de fond et vous verrez son icône dans la barre d'état, à droite de votre barre des tâches.
Mais attention : là, vous avez juste lancé le serveur. Il est prêt à recevoir un modèle, mais pour l'instant il n'en possède ni n'en exécute aucun. Il va donc falloir lui donner un modèle à exécuter, et pour ce faire, commencer par en choisir un. Car oui, il y a plusieurs versions de LLaMa 3.
Pour ce faire, il faut commencer par retourner sur le site officiel d'Ollama, cliquer sur le lien "Models" (en haut à droite) puis sélectionner llama 3.
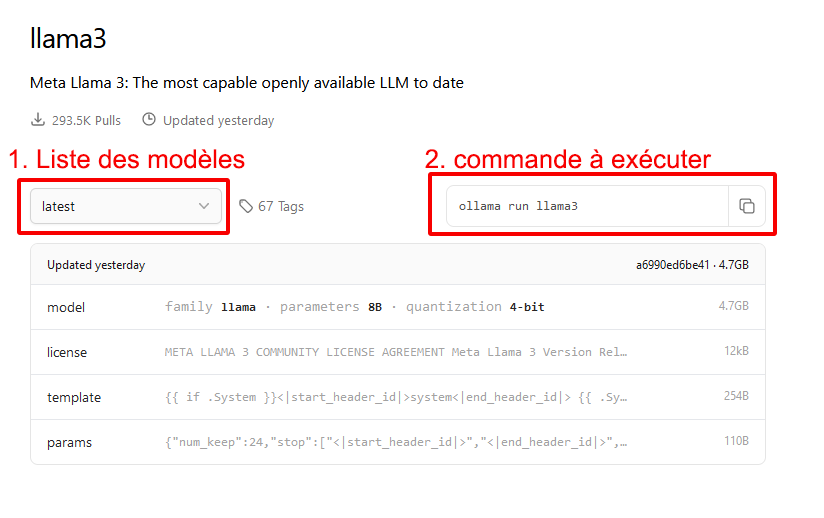
Vous arrivez sur cette page. À gauche, la liste des modèles disponibles, à faire dérouler. À droite, la commande que vous devrez utiliser pour demander à ollama de télécharger (si nécessaire) et de lancer ce modèle.
Quel modèle choisir ?
Ah, là, on entre dans le dur. La réponse dépend de plusieurs facteurs :
- La puissance de votre PC, la quantité de RAM et de VRAM que vous possédez
- Le niveau d'intelligence que vous attendez du modèle
- Votre patience
Pour résumer, comme on le disait, il existe deux grands types de modèles pour LLaMa 3 : 8B et 70B. Le modèle 70B est certes nettement plus intelligent que le modèle 8B, mais il est aussi nettement plus volumineux. Problème : s'il est plus gros que la VRAM disponible sur votre carte graphique, alors une partie du modèle ira sur la RAM générale de votre PC, ce qui le ralentira beaucoup. Pire : un gros modèle peut ne pas tenir du tout dans votre RAM disponible, même en mettant bout à bout votre RAM et votre VRAM.
Pour limiter une partie de ce problème, la communauté a pratiqué différents niveaux de ce que l'on appelle une quantisation. Cette quantisation consiste à rendre le modèle plus approximatif, en faisant en sorte que ses calculs soient faits avec une précision arithmétique moindre. Avantage : ça le rend plus rapide et nettement moins volumineux. Inconvénient : les plus gros niveaux de quantisation le rendent aussi plus idiot.
À tel point qu'une question peut se poser : est-ce qu'il faut privilégier un 70B extrêmement quantisé, ou un 8B peu quantisé ? C'est une vraie question. La réponse est que globalement, un 70B même quantisé à l'extrême tend à être un peu plus futé que le 8B même non-quantisé, en tout cas dans les tâches de raisonnement. Ce n'est pas forcément vrai dans toutes les tâches de rédaction.
OK mais ça ne répond pas à ma question : quel modèle au final ?
C'est un peu à voir au cas par cas, mais à supposer que vous ayez un PC milieu de gamme, équipé d'un GPU doté de 8 ou 16Go de VRAM typiquement et de 32Go de RAM principale, vous allez devoir faire un premier choix :
- Soit vous souhaitez une génération relativement rapide, semblable en vitesse à ce que produit ChatGPT, et il faudra partir sur un modèle 8B.
- Soit vous êtes prêts à supporter une génération lente, voire très lente, et vous êtes prêt à confier toute votre RAM et toute votre VRAM à LLaMa, et vous pouvez partir sur un 70B quantisé.
Si vous partez sur un modèle 8B : C'est la solution la plus simple et la plus raisonnable sur un PC, disons, "normal" (et pas une station de travail avec des quantités démentielles de RAM).
Choisissez un niveau de quantisation tel que la totalité du modèle peut tenir dans la VRAM de votre carte graphique, tout en laissant encore 1 ou 2 Go de marge pour vos autres besoins (du genre... afficher vos fenêtres, tout simplement). Par exemple pour un GPU doté de 8Go de VRAM, le modèle 8B-instruct-q6_K fera bien l'affaire. Comme vous le voyez dans la liste, il occupera 6,6Go de VRAM, et laissera donc 1,4Go de libre pour vos besoins GPU de base, ce qui est suffisant. Une quantisation à 6 bits offre de surcroît un modèle assez proche de l'original, avec très peu de perte "d'intelligence".
Si vous désirez un peu plus de marge, le 8B-instruct-q5_K_M. Celui-ci en occupe 5,7Go et vous laissera donc 2,3Go de libre. De quoi regarder tranquillement une vidéo en HD à côté, avoir des fenêtres d'ouvertes, et autres usages de base consommateurs de VRAM.
Il n'est pas vraiment nécessaire d'aller sur un modèle moins quantisé que q6 (c'est-à-dire avec une précision de 6 bits). Dans l'ensemble, il n'y a pas de perte significative d'intelligence au-dessus de 6 bits. En revanche, à partir de 5 bits, la différence commence à se faire sentir.
Si vous partez sur un modèle 70B : Alors là ça se complique, il va falloir choisir un niveau de quantisation tel que la totalité du modèle peut tenir sur votre PC tout court... oubliez même l'idée que ça tourne en entier sur votre GPU : les modèles 70B les plus quantisés font 26Go, tandis que même une RTX 4090, le plus gros GPU grand public du moment, ne possède que 24Go. À moins d'être carrément équipé de DEUX RTX 4090, vous aurez donc forcément une partie du modèle en RAM générale, c'est inévitable. Prenez donc un modèle qui puisse tenir sur votre GPU + RAM générale, toujours en laissant un peu de marge au GPU, mais aussi à la RAM centrale qui doit continuer à faire tourner vos logiciels, votre OS etc.
La situation exacte dépend de notre machine, mais pour donner un ordre d'idée, nous avons constaté que sur un PC équipé d'un Ryzen 5 3600, de 32Go de RAM à 3000MHz, d'une RTX 2060 Super avec 8Go de VRAM, le modèle le plus gros que l'on puisse faire tourner est le 70B-instruct-q3_K_S. En ne laissant ouvert que lui, Chatbox (sur lequel on va revenir après), Windows, et une poignée de logiciels très basiques, nous avions 98% de la RAM générale et 90% de la VRAM occupés. Et nous générions des réponses à la vitesse de seulement 0,4 token par seconde (+ de 2,5 seconde par token). Cela revient grosso-modo à générer 1 mot complet toutes les 4 secondes. C'est ATROCEMENT lent. Une réponse un peu longue à une question pouvait ainsi prendre plus de dix minutes, voire un quart d'heure. Et il était hors de question de lancer Office ou Chrome en même temps, il n'y avait tout simplement pas la place en RAM pour ça.
Vous l'aurez compris : à part pour l'expérience, les modèles 70B sont à réserver aux très grosses configs. Les PC milieux de gamme qui veulent quelque chose d'exploitable partirons plus volontiers sur un module 8B, quitte à le quantiser peu. Ils y gagneront énormément de confort d'utilisation, et une vitesse plusieurs dizaines voire plusieurs centaines de fois supérieure.
Instruct ou text ?
Vous avez peut-être remarqué que les modèles 70B comme 8B, et à différents niveaux de quantisation, étaient disponibles en version "instruct" ou "text".
Les versions "text" sont les modèles de base. Non-finetunés, ils sont assez généralistes et polyvalents, mais plus à l'aise quand on leur confie un début de texte en amorce et qu'on leur demande ensuite de compléter. Les usages peuvent être nombreux et correspondent au modèle brut. C'est l'équivalent d'accéder directement à GPT4 via l'API d'OpenAI.
Les versions "instruct" sont des modèles fine-tunés pour recevoir des instructions. Ces instructions sont généralement de type "comporte-toi comme un chatbot" et sont donc plus appropriées pour une utilisation sous forme de dialogue, à la manière d'un ChatGPT.
Bien entendu, rien n'empêche de faire compléter du texte à un modèle instruct (après tout il suffit... de lui en donner l'instruction), et rien n'empêche de dialoguer avec le modèle texte. Mais vous obtiendrez probablement de meilleurs résultats en utilisant le modèle le plus adapté à vos usages.
Généralement, si vous souhaitez juste discuter avec LLaMa, et que vous ne souhaitez ni le fine-tuner vous-même, ni en faire un usage particulier via une API, il vaut mieux partir sur un modèle instruct.
Je sais désormais quel modèle je veux utiliser. Maintenant je fais quoi ?
Reprenez la capture d'écran ci-dessus : choisissez le modèle que vous souhaitez utiliser dans la liste déroulante (cadre rouge n°1) et regardez le cadre rouge n°2 : c'est la commande que vous devrez saisir pour lancer le modèle (et le télécharger si besoin).
Vous avez précédemment installé et lancé ollama, maintenant ouvrez le menu démarrer de Windows, copiez-coller la commande depuis le cadre n°2, par exemple :
ollama run llama3:8b-instruct-q6_K
Puis, appuyez sur Entrée. Si tout se passe bien, une fenêtre de ligne de commande s'ouvre, et ollama commence à télécharger le modèle (si vous ne le possédez pas déjà) puis le lance. Attention, les modèles sont volumineux : assurez-vous de disposer d'assez d'espace disque, et d'assez de RAM bien sûr, pour que tout fonctionne. Sinon, vous recevrez un message d'erreur. Heureusement, les messages d'erreur sont plutôt clairs quant au problème rencontré, ce qui rend le debugging assez facile.
Si vous voyez une fenêtre s'ouvrir un quart de seconde et se refermer aussitôt, c'est probablement que vous n'avez pas lancé ollama auparavant. Retournez donc dans le Menu Démarrer, cherchez l'icône Ollama (ou tapez ollama directement) et lancez-le sans commande. Son icône doit apparaître dans votre barre de notification, à droite de la barre des tâches. Une fois ceci fait, vous pouvez à nouveau taper la commande pour charger un modèle en particulier. Et cette fois, cela devrait fonctionner.
Une fois le modèle téléchargé et lancé, une invite apparaît dans la fenêtre de ligne de commande et à ce stade, vous pouvez déjà discuter avec LLaMa, directement dans l'invite de commande. Cependant, ce n'est pas très agréable.
C'est donc là qu'intervient Chatbox.
Chatbox, l'interface pour discuter avec LLaMa
Chatbox est un logiciel gratuit (vous trouverez le lien de téléchargement en bas de cet article) qui permet de discuter avec différents LLM en local via une interface conviviale.
Une fois téléchargé et installé, vous arrivez sur une interface qui ressemble à n'importe quel logiciel de messagerie :

Mais avant de converser avec, il va falloir le paramétrer.
Rendez-vous donc dans la section Paramètres pour définir des paramètres qui s'appliqueront par défaut à toutes vos conversations. Rassurez-vous, vous pourrez ultérieurement définir des configurations particulières pour vos différentes conversations.
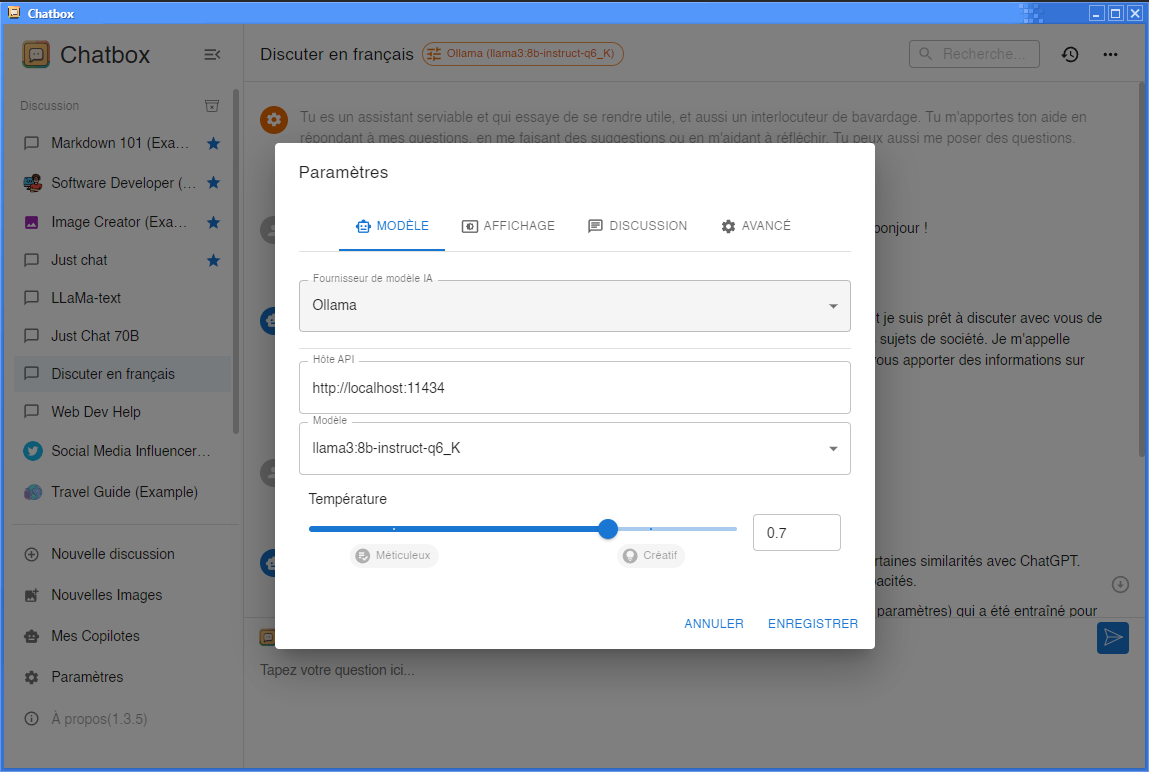
Quelques réglages de base, comme indiqués sur la capture d'écran ci-dessus :
Fournisseur de modèle d'IA : choisissez ollama
Hôte API : laissez les paramètres par défaut, sauf si vous avez des raisons particulières d'en changer (auquel cas vous savez probablement déjà ce que vous faites)
Modèle : en principe, il détecte automatiquement le modèle actuellement lancé sous ollama. Si ce n'est pas le cas, vous pouvez l'entrer ici.
Température : vous devez ici choisir à quel point le modèle sera déterministe (et donc précis), ou aléatoire (et donc créatif). Plus vous choisissez une température basse, moins le modèle déviera du résultat jugé "statistiquement optimal". Avec une température à 0, si le contexte est strictement identique, le modèle répondra toujours la même chose. Alors que si la température est élevée, même avec un contexte identique, il pourra prendre des libertés... au risque de finir à côté de la plaque. C'est à vous de choisir ce qui vous convient.
Avant d'enregistrer, rendez-vous dans l'onglet Discussion.
Vous vous souvenez quand je vous ai dit de choisir le modèle "instruct" pour une expérience proche de ChatGPT ? C'est justement ici que vous allez entrer votre instruction à LLaMa. Ce texte conditionnera son comportement, donc choisissez bien. Écrivez-lui un prompt en français si vous souhaitez privilégier une discussion francophone avec lui. Si vous ne le faites pas, il aura tendance à repasser à l'anglais.
Vous pouvez par exemple lui dire "Tu es un assistant serviable qui répond à toutes mes questions." Ou bien "Tu es un développeur web, tu développes en JS et typescript. Tu m'aides à écrire du code propre et optimisé." Vous pouvez bien sûr ajouter des détails, mais attention : la fenêtre de contexte de LLaMa 3 est assez faible, ne soyez pas excessivement verbeux.
Vous pouvez dès à présent Enregistrer et lancer une conversation avec LLaMa 3.
Mais poussons un peu plus loin : que diriez-vous de préparer plusieurs conversations avec plusieurs cas d'usages ?
Créez une nouvelle discussion en cliquant sur Nouvelle discussion, et nous allons à présent la configurer. Trois points nous intéressent.

- Donnez ici un nom à votre conversation, pour la retrouver facilement dans la barre latérale gauche.
- Vous pouvez ici éditer ce texte : il s'agit du prompt de départ, "l'instruction" dont on parlait plus haut. Vous pouvez ainsi personnaliser le prompt système, et donc le comportement, du modèle conversation par conversation. Vous pouvez ainsi avoir une conversation spécialisée développement, une conversation généraliste, une conversation en anglais, etc.
- Enfin, ici, vous pouvez accéder aux paramètres système de la conversation... ainsi, si vous comptez utiliser plusieurs modèles, et avoir des conversations différentes, vous le pouvez, en modifiant les paramètres de chaque conversation individuellement. Vous pouvez par exemple avoir une conversation spécialement pour le modèle 8B et une autre spécialement pour le modèle 70B. Vous pouvez également modifier la température, et ainsi avoir une conversation plus précise/déterministe, et une autre plus créative.
Voilà, vous pouvez à présent discuter avec LLaMa comme vous le voulez, avoir plusieurs conversations parallèles avec lui, Chatbox s'occupe de faire la liaison, il conserve le contexte et l'historique de votre discussion. Et tout ça en local, en préservant votre vie privée !
Il ne reste plus qu'à vous amuser.
| Ressources : |
|---|
